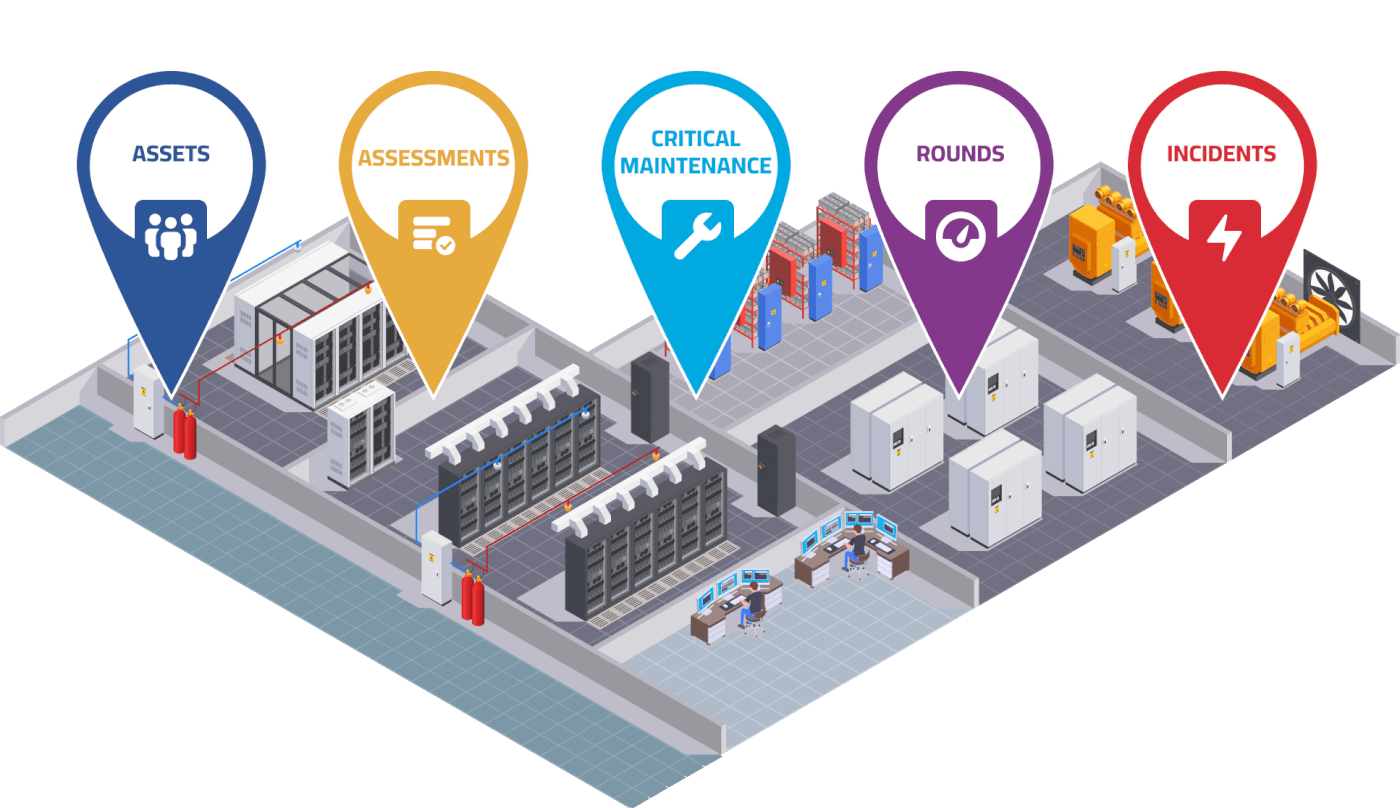
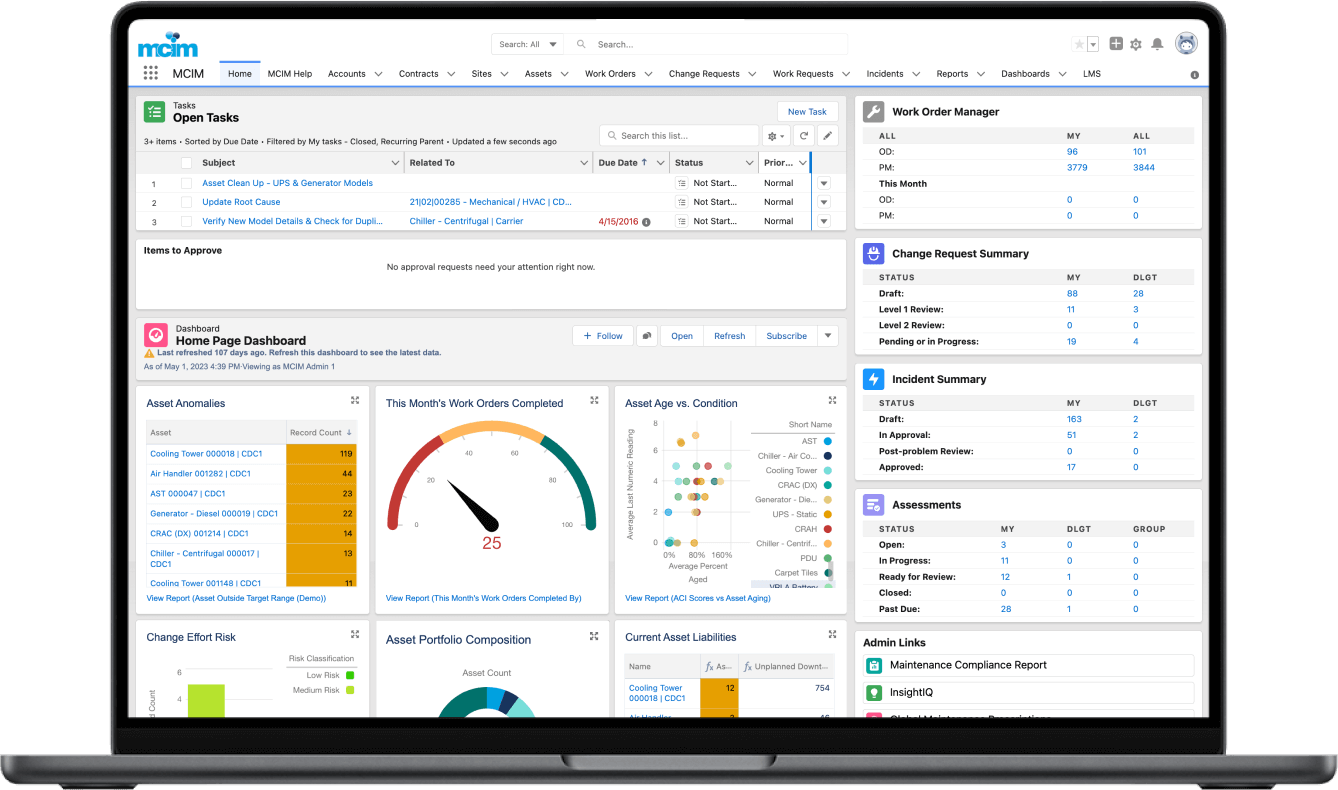
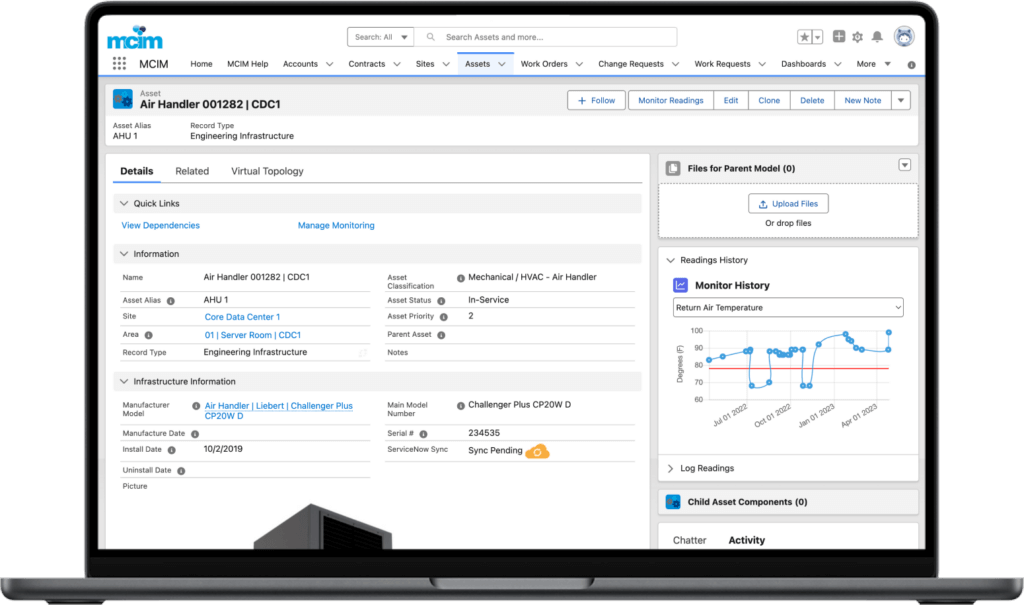
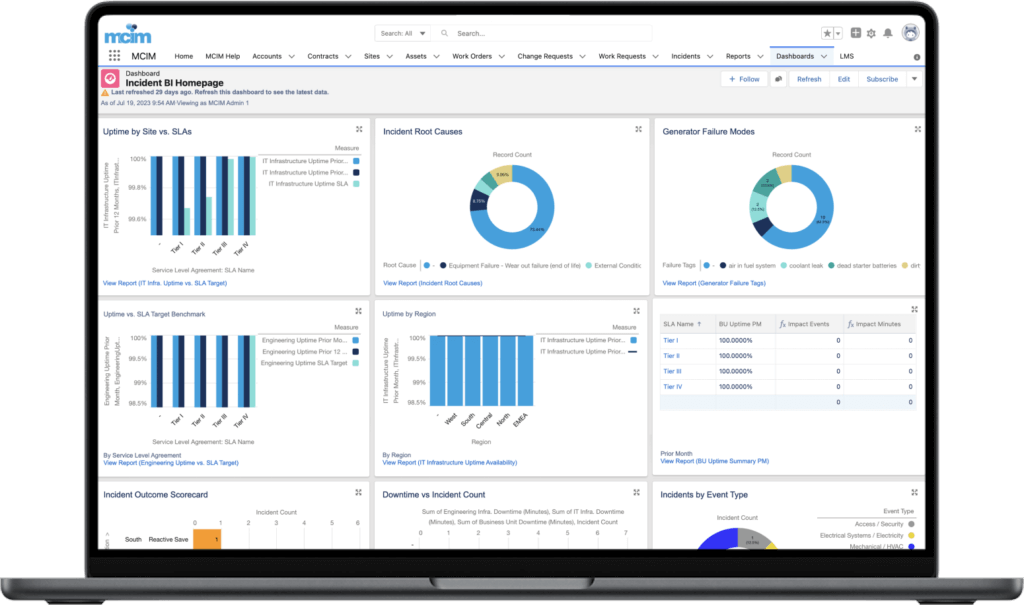
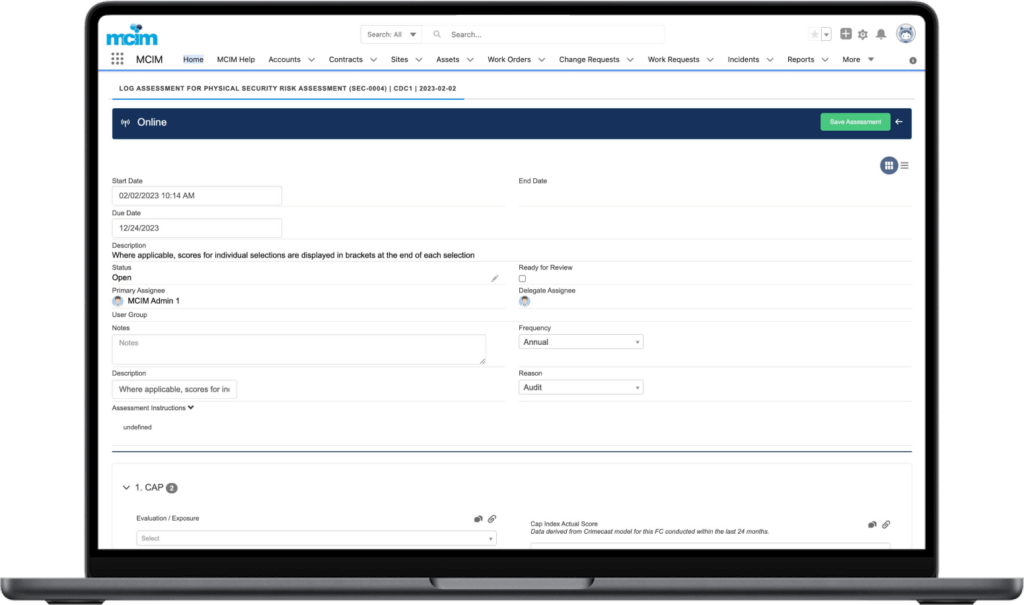
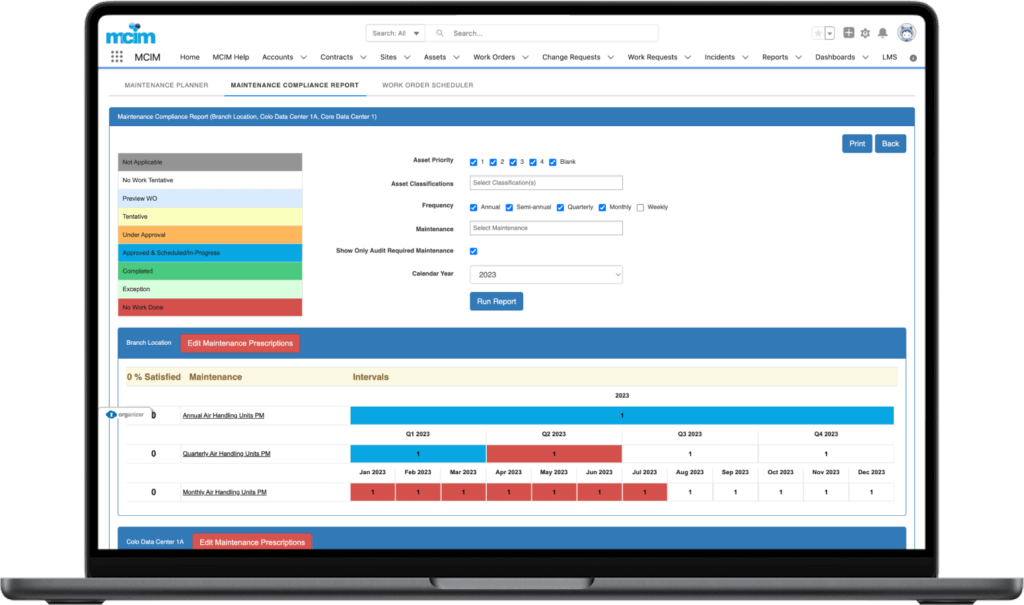
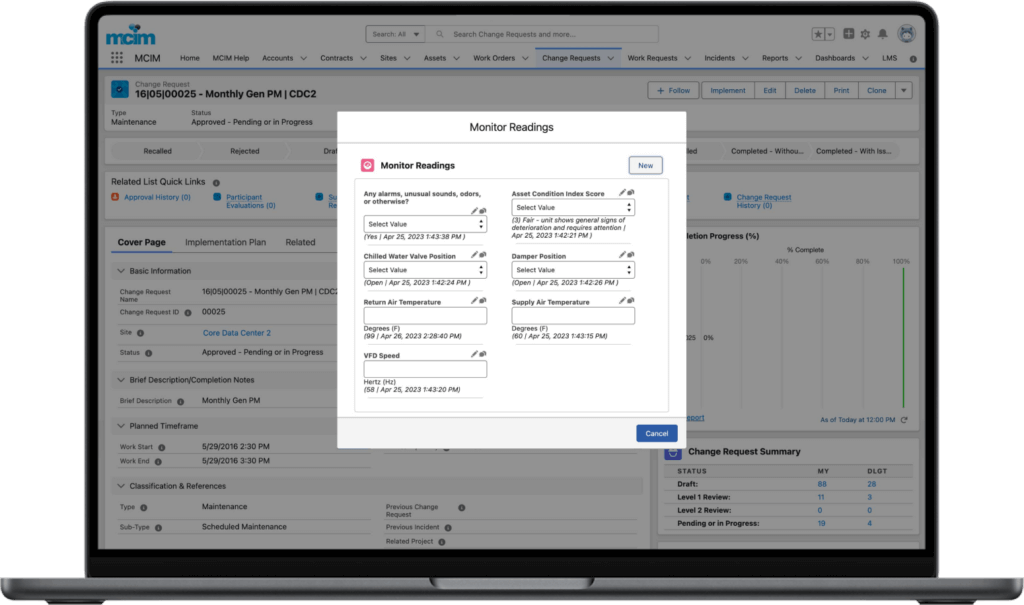
When a client needed a solution to provide actionable insight to inform a tactical approach to preventable incidents caused by human error, MCIM helped, leading to a 32% reduction in preventable human error incidents within three months and a sustained reduction of preventable human error incidents by 84% 18 months after implementing the program.